Existing video personalization methods preserve visual likeness but treat video and audio separately. Without access to the visual scene, audio models cannot synchronize sounds with on-screen actions; and because classical voice-cloning models condition only on a reference recording, a text prompt cannot redirect speaking style or acoustic environment. Although prompt-conditioned audio models could offer such control, they lack access to the visual scene.
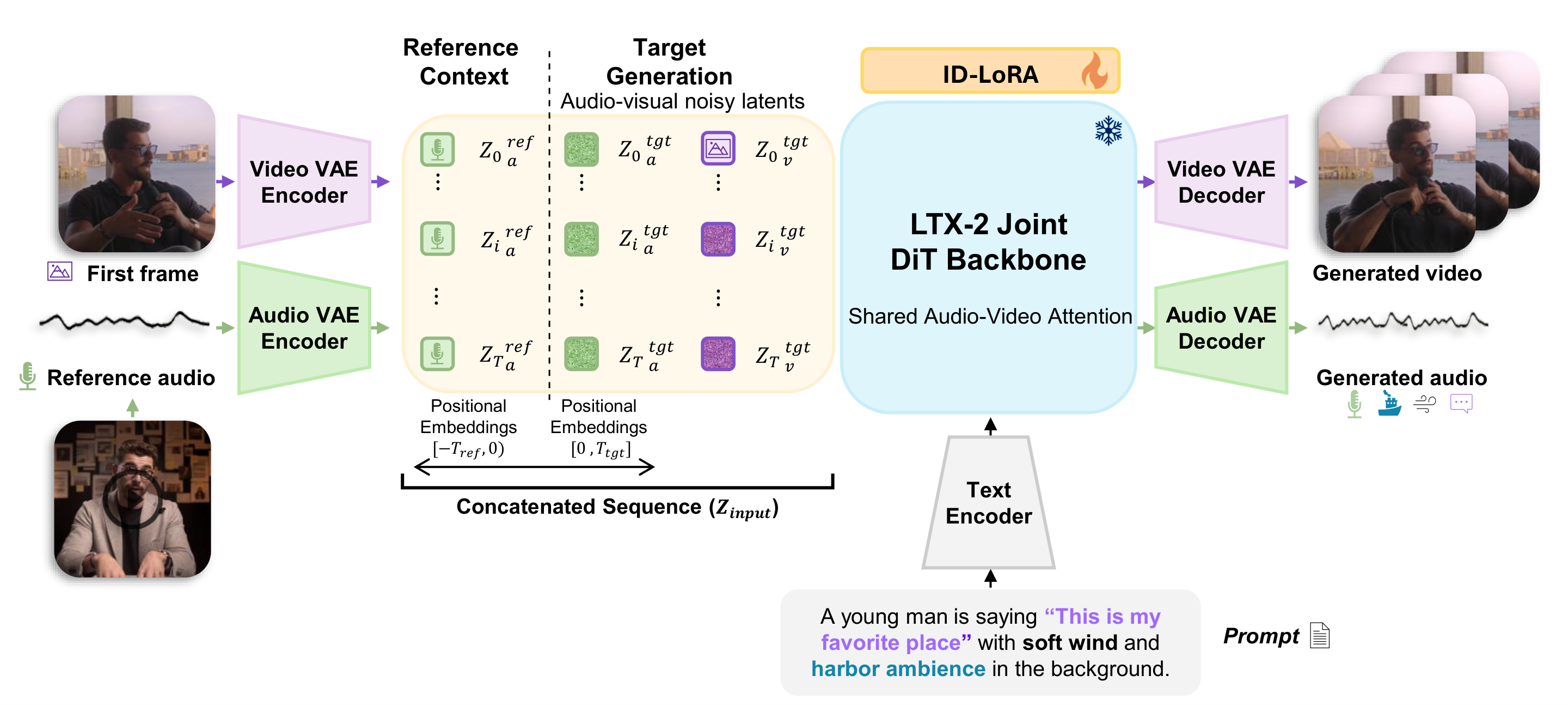
We propose ID-LoRA (Identity-Driven In-Context LoRA), which jointly generates a subject's appearance and voice in a single model, letting a text prompt, a reference image, and a short audio clip govern both modalities together. ID-LoRA adapts the LTX-2 joint audio-video diffusion backbone via parameter-efficient In-Context LoRA and, to our knowledge, is the first method to personalize visual appearance and voice within a single generative pass. Two challenges arise from this formulation. Reference and generation tokens share the same positional-encoding space, making them hard to distinguish; we address this with negative temporal positions, which place reference tokens in a disjoint region of the RoPE space while preserving their internal temporal structure. Furthermore, speaker characteristics tend to be diluted during denoising; we introduce identity guidance, a classifier-free guidance variant that amplifies speaker-specific features by contrasting predictions with and without the reference signal.
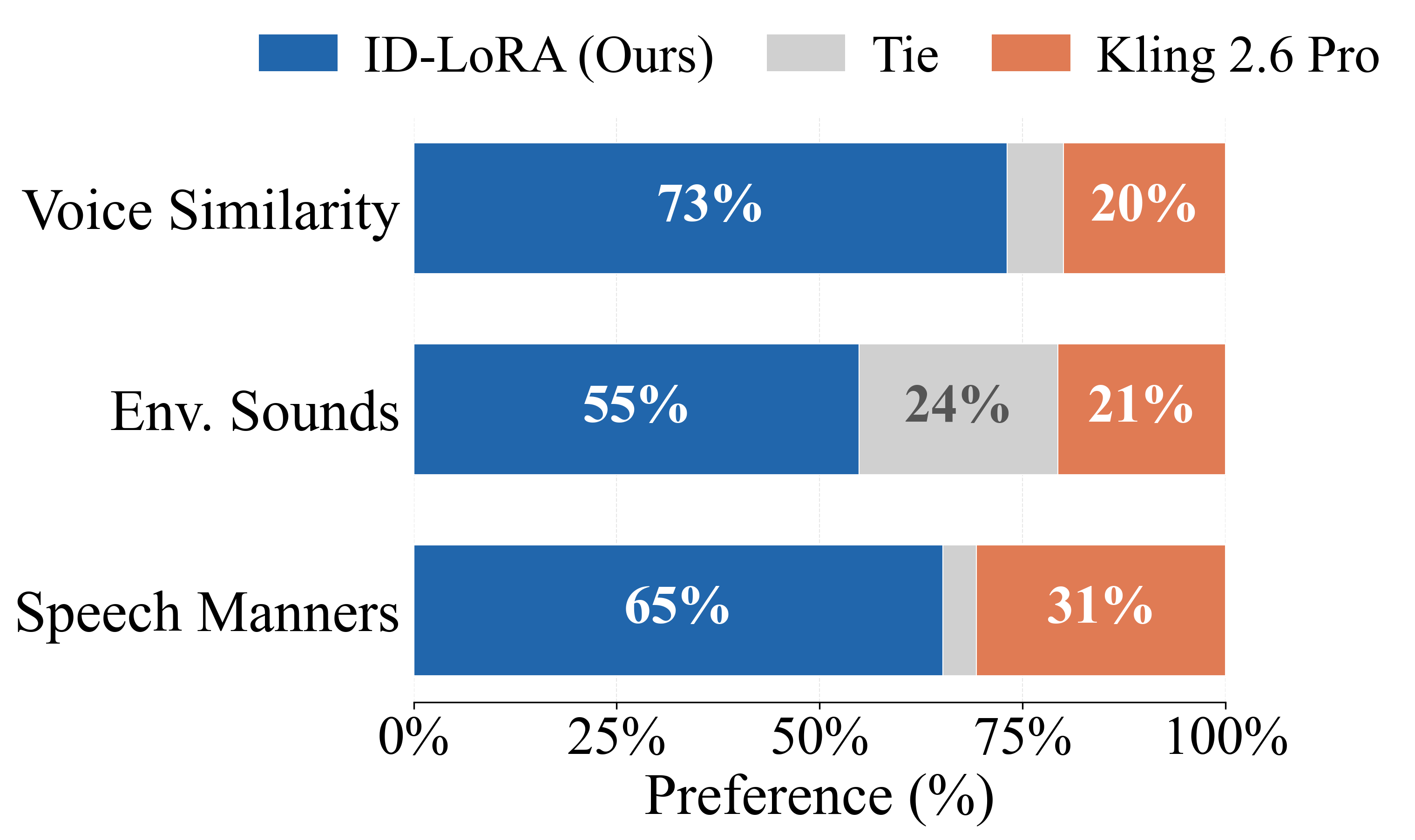
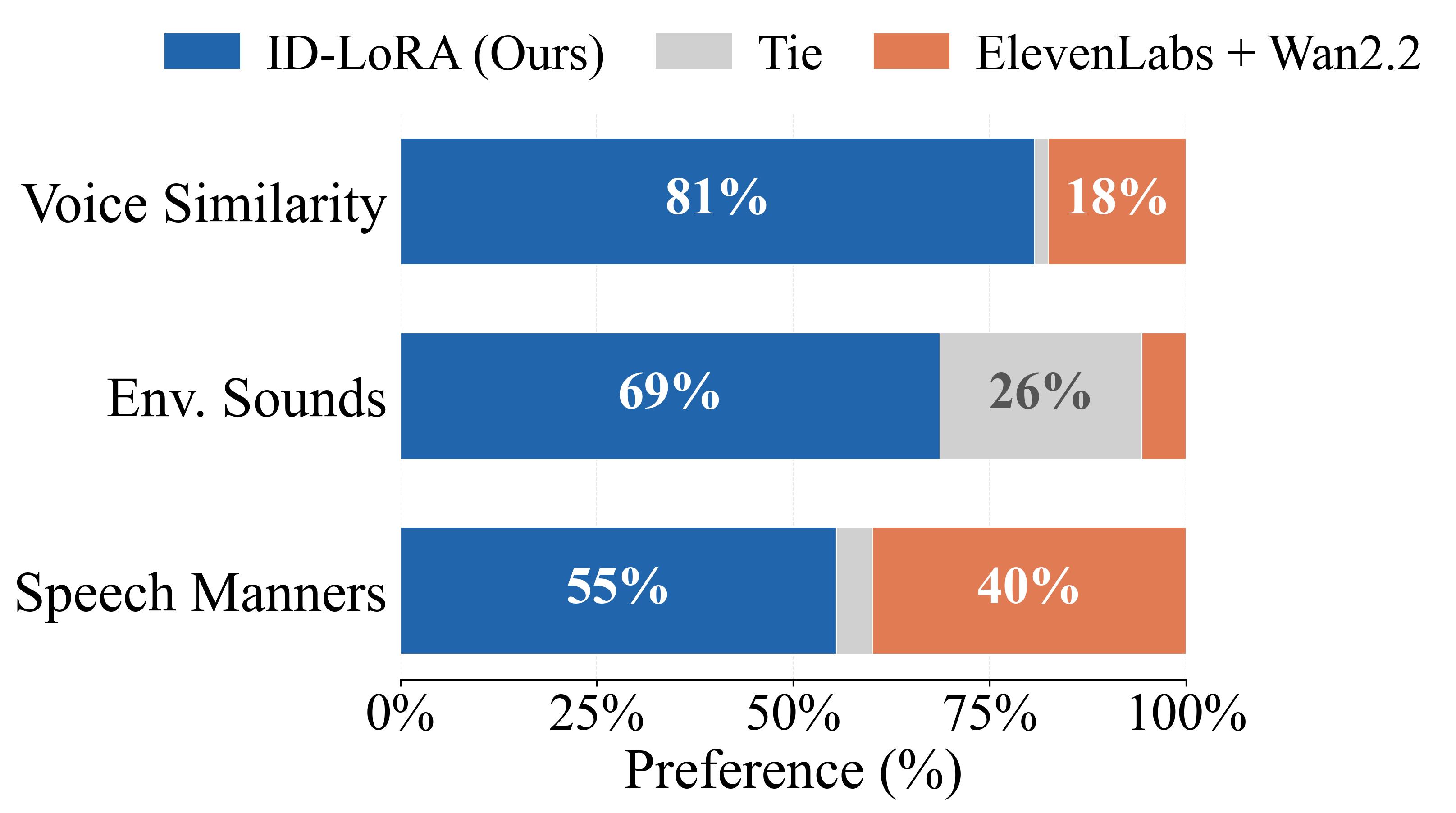
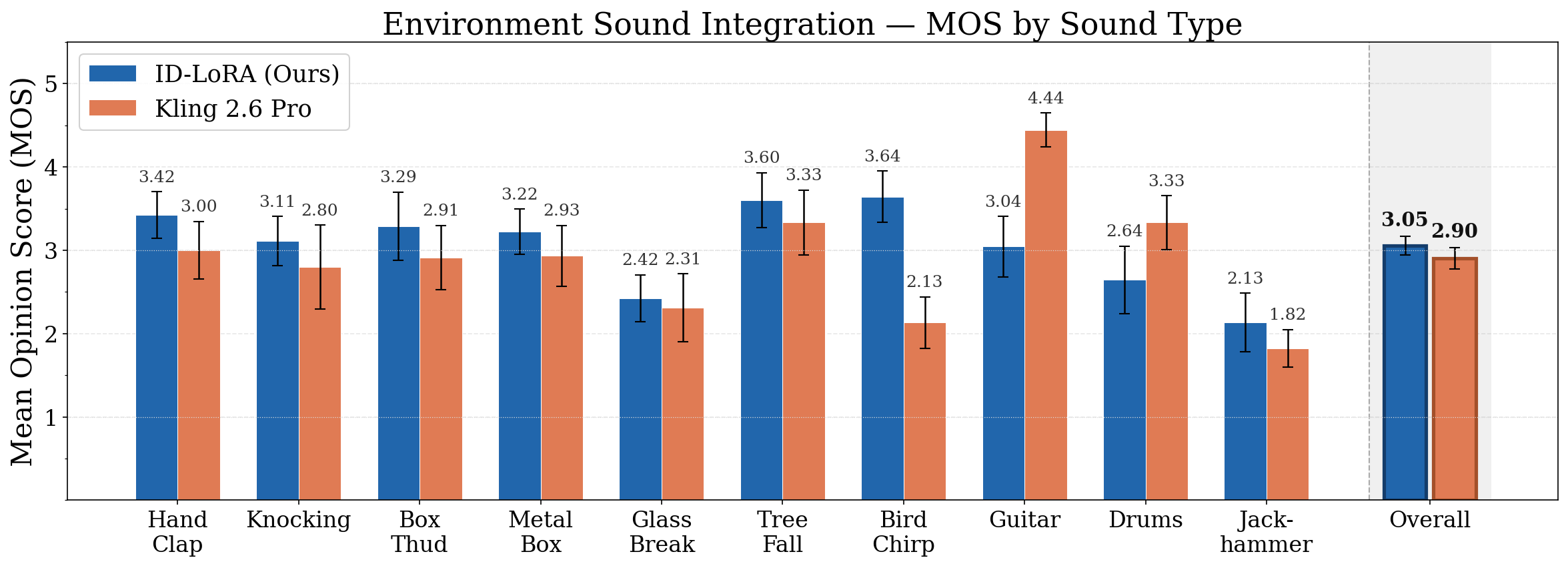
In human preference studies ID-LoRA is preferred over Kling 2.6 Pro, the leading commercial unified model with voice personalization capabilities, by 73% of annotators for voice similarity and 65% for speaking style. Automatic metrics confirm these gains: on cross-environment settings, speaker similarity improves by 24% over Kling, with the gap widening as reference and target conditions diverge. ID-LoRA achieves these results with only approximately 3K training pairs on a single GPU.